-
Latest Version
-
Operating System
macOS 10.13 High Sierra or later
-
User Rating
Click to vote -
Author / Product
-
Filename
postgresql-16.3-1-osx.dmg
Sometimes latest versions of the software can cause issues when installed on older devices or devices running an older version of the operating system.
Software makers usually fix these issues but it can take them some time. What you can do in the meantime is to download and install an older version of PostgreSQL 16.3.
For those interested in downloading the most recent release of PostgreSQL for Mac or reading our review, simply click here.
All old versions distributed on our website are completely virus-free and available for download at no cost.
We would love to hear from you
If you have any questions or ideas that you want to share with us - head over to our Contact page and let us know. We value your feedback!
-
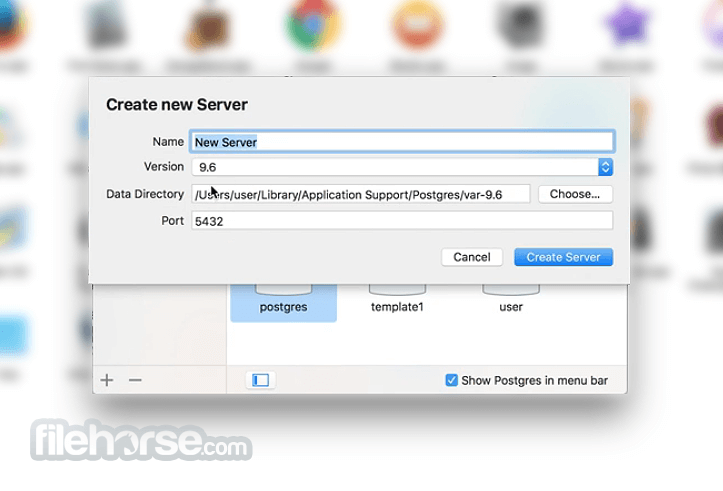
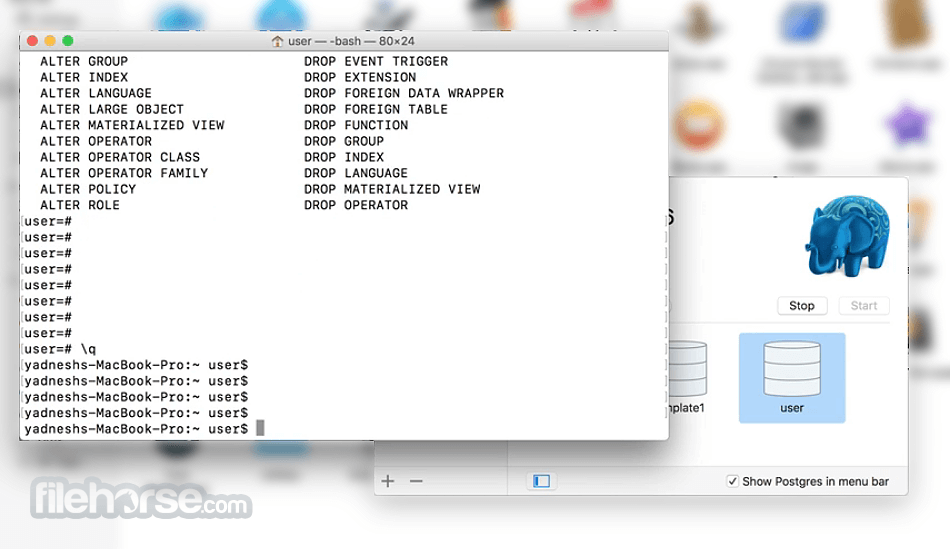
PostgreSQL 16.3 Screenshots
The images below have been resized. Click on them to view the screenshots in full size.

-
-
What's new in this version:
Changed:
- Restrict visibility of pg_stats_ext and pg_stats_ext_exprs entries to the table owner
- These views failed to hide statistics for expressions that involve columns the accessing user does not have permission to read. View columns such as most_common_vals might expose security-relevant data. The potential interactions here are not fully clear, so in the interest of erring on the side of safety, make rows in these views visible only to the owner of the associated table.
- The PostgreSQL Project thanks Lukas Fittl for reporting this problem
- By itself, this fix will only fix the behavior in newly initdb'd database clusters. If you wish to apply this change in an existing cluster, you will need to do the following:
- Find the SQL script fix-CVE-2024-4317.sql in the share directory of the PostgreSQL installation
- In each database of the cluster, run the fix-CVE-2024-4317.sql script as superuser. In psql this would look like
- i /usr/share/postgresql/fix-CVE-2024-4317.sql
-
- Do not forget to include the template0 and template1 databases, or the vulnerability will still exist in databases you create later. To fix template0, you'll need to temporarily make it accept connections. Do that with
- ALTER DATABASE template0 WITH ALLOW_CONNECTIONS true
- and then after fixing template0, undo it with
- ALTER DATABASE template0 WITH ALLOW_CONNECTIONS false
- Fix INSERT from multiple VALUES rows into a target column that is a domain over an array or composite type
- Such cases would either fail with surprising complaints about mismatched datatypes, or insert unexpected coercions that could lead to odd results.
- Require SELECT privilege on the target table for MERGE with a DO NOTHING clause
- SELECT privilege would be required in all practical cases anyway, but require it even if the query reads no columns of the target table. This avoids an edge case in which MERGE would require no privileges whatever, which seems undesirable even when it's a do-nothing command.
- Fix handling of self-modified tuples in MERGE
- Throw an error if a target row joins to more than one source row, as required by the SQL standard.
- Fix incorrect pruning of NULL partition when a table is partitioned on a boolean column and the query has a boolean IS NOT clause
- A NULL value satisfies a clause such as boolcol IS NOT FALSE, so pruning away a partition containing NULLs yielded incorrect answers.
- Make ALTER FOREIGN TABLE SET SCHEMA move any owned sequences into the new schema
- Moving a regular table to a new schema causes any sequences owned by the table to be moved to that schema too
- Make ALTER TABLE ... ADD COLUMN create identity/serial sequences with the same persistence as their owning tables
- CREATE UNLOGGED TABLE will make any owned sequences be unlogged too. ALTER TABLE missed that consideration, so that an added identity column would have a logged sequence, which seems pointless.
- Improve ALTER TABLE ... ALTER COLUMN TYPE's error message when there is a dependent function or publication
- In CREATE DATABASE, recognize strategy keywords case-insensitively for consistency with other options
- Fix EXPLAIN's counting of heap pages accessed by a bitmap heap scan
- Previously, heap pages that contain no visible tuples were not counted; but it seems more consistent to count all pages returned by the bitmap index scan.
- Fix EXPLAIN's output for subplans in MERGE
- EXPLAIN would sometimes fail to properly display subplan Params referencing variables in other parts of the plan tree.
- Avoid deadlock during removal of orphaned temporary tables
- If the session that creates a temporary table crashes without removing the table, autovacuum will eventually try to remove the orphaned table. However, an incoming session that's been assigned the same temporary namespace will do that too. If a temporary table has a dependency
- Fix updating of visibility map state in VACUUM with the DISABLE_PAGE_SKIPPING option
- Due to an oversight, this mode caused all heap pages to be dirtied, resulting in excess I/O. Also, visibility map bits that were incorrectly set would not get cleared.
- Avoid race condition while examining per-relation frozen-XID values
- VACUUM's computation of per-database frozen-XID values from per-relation values could get confused by a concurrent update of those values by another VACUUM.
- Fix buffer usage reporting for parallel vacuuming
- Buffer accesses performed by parallel workers were not getting counted in the statistics reported in VERBOSE mode.
- Ensure that join conditions generated from equivalence classes are applied at the correct plan level
- In versions before PostgreSQL 16, it was possible for generated conditions to be evaluated below outer joins when they should be evaluated above
- Fix “could not find pathkey item to sort” errors occurring while planning aggregate functions with ORDER BY or DISTINCT options
- This is similar to a fix applied in 16.1, but it solves the problem for parallel plans.
- Prevent potentially-incorrect optimization of some window functions
- Disable “run condition” optimization of ntile() and count() with non-constant arguments. This avoids possible misbehavior with sub-selects, typically leading to errors like “WindowFunc not found in subplan target lists”.
- Avoid unnecessary use of moving-aggregate mode with a non-moving window frame
- When a plain aggregate is used as a window function, and the window frame start is specified as UNBOUNDED PRECEDING, the frame's head cannot move so we do not need to use the special
- Avoid use of already-freed data while planning partition-wise joins under GEQO
- This would typically end in a crash or unexpected error message.
- Avoid freeing still-in-use data in Memoize
- In production builds this error frequently didn't cause any problems, as the freed data would most likely not get overwritten before it was used.
- Fix incorrectly-reported statistics kind codes in “requested statistics kind X is not yet built” error messages
- Use a hash table instead of linear search for “catcache list” objects
- This change solves performance problems that were reported for certain operations in installations with many thousands of roles.
- Be more careful with RECORD-returning functions in FROM
- The output columns of such a function call must be defined by an AS clause that specifies the column names and data types. If the actual function output value doesn't match that, an error is supposed to be thrown at runtime. However, some code paths would examine the actual value prematurely, and potentially issue strange errors or suffer assertion failures if it doesn't match expectations.
- Fix confusion about the return rowtype of SQL-language procedures
- A procedure implemented in SQL language that returns a single composite-type column would cause an assertion failure or core dump.
- Add protective stack depth checks to some recursive functions
- Fix mis-rounding and overflow hazards in date_bin()
- In the case where the source timestamp is before the origin timestamp and their difference is already an exact multiple of the stride, the code incorrectly subtracted the stride anyway. Also, detect some integer-overflow cases that would have produced incorrect results.
- Detect integer overflow when adding or subtracting an interval to/from a timestamp
- Some cases that should cause an out-of-range error produced an incorrect result instead.
- Avoid race condition in pg_get_expr()
- If the relation referenced by the argument is dropped concurrently, the function's intention is to return NULL, but sometimes it failed instead.
- Fix detection of old transaction IDs in XID status functions
- Transaction IDs more than 231 transactions in the past could be misidentified as recent, leading to misbehavior of pg_xact_status() or txid_status().
- Ensure that a table's freespace map won't return a page that's past the end of the table
- Because the freespace map isn't WAL-logged, this was possible in edge cases involving an OS crash, a replica promote, or a PITR restore. The result would be a “could not read block” error.
- Fix file descriptor leakage when an error is thrown while waiting in WaitEventSetWait
- Avoid corrupting exception stack if an FDW implements async append but doesn't configure any wait conditions for the Append plan node to wait for
- Throw an error if an index is accessed while it is being reindexed
- Previously this was just an assertion check, but promote it into a regular runtime error. This will provide a more on-point error message when reindexing a user-defined index expression that attempts to access its own table.
- Ensure that index-only scans on name columns return a fully-padded value
- The value physically stored in the index is truncated, and previously a pointer to that value was returned to callers. This provoked complaints when testing under valgrind. In theory it could result in crashes, though none have been reported.
- Fix race condition that could lead to reporting an incorrect conflict cause when invalidating a replication slot
- Fix race condition in deciding whether a table sync operation is needed in logical replication
- An invalidation event arriving while a subscriber identifies which tables need to be synced would be forgotten about, so that any tables newly in need of syncing might not get processed in a timely fashion.
- Fix crash with DSM allocations larger than 4GB
- Disconnect if a new server session's client socket cannot be put into non-blocking mode
- It was once theoretically possible for us to operate with a socket that's in blocking mode; but that hasn't worked fully in a long time, so fail at connection start rather than misbehave later.
- Fix inadequate error reporting with OpenSSL 3.0.0 and later
- System-reported errors passed through by OpenSSL were reported with a numeric error code rather than anything readable.
- Fix thread-safety of error reporting for getaddrinfo() on Windows
- A multi-threaded libpq client program could get an incorrect or corrupted error message after a network lookup failure.
- Avoid concurrent calls to bindtextdomain() in libpq and ecpglib
- Although GNU gettext's implementation seems to be fine with concurrent calls, the version available on Windows is not.
- Fix crash in ecpg's preprocessor if the program tries to redefine a macro that was defined on the preprocessor command line
- In ecpg, avoid issuing false “unsupported feature will be passed to server” warnings
- Ensure that the string result of ecpg's intoasc() function is correctly zero-terminated
- In initdb's -c option, match parameter names case-insensitively
- The server treats parameter names case-insensitively, so this code should too. This avoids putting redundant entries into the generated postgresql.conf file.
- In psql, avoid leaking a query result after the query is cancelled
- This happened only when cancelling a non-last query in a query string made with ; separators.
- Fix pg_dumpall so that role comments, if present, will be dumped regardless of the setting of --no-role-passwords
- Skip files named .DS_Store in pg_basebackup, pg_checksums, and pg_rewind
- This avoids problems on macOS, where the Finder may create such files.
- Fix PL/pgSQL's parsing of single-line comments
- This mistake caused parse errors if such a comment followed a WHEN expression in a PL/pgSQL CASE statement.
- In contrib/amcheck, don't report false match failures due to short- versus long-header values
- A variable-length datum in a heap tuple or index tuple could have either a short or a long header, depending on compression parameters that applied when it was made. Treat these cases as equivalent rather than complaining if there's a difference.
- Fix bugs in BRIN output functions
- These output functions are only used for displaying index entries in contrib/pageinspect, so the errors are of limited practical concern.
- In contrib/postgres_fdw, avoid emitting requests to sort by a constant
- This could occur in cases involving UNION ALL with constant-emitting subqueries. Sorting by a constant is useless of course, but it also risks being misinterpreted by the remote server, leading to “ORDER BY position N is not in select list” errors.
- Make contrib/postgres_fdw set the remote session's time zone to GMT not UTC
- This should have the same results for practical purposes. However, GMT is recognized by hard-wired code in the server, while UTC is looked up in the timezone database. So the old code could fail in the unlikely event that the remote server's timezone database is missing entries.
- In contrib/xml2, avoid use of library functions that have been deprecated in recent versions of libxml2
- Fix incompatibility with LLVM 18
- Allow make check to work with the musl C library
 OperaOpera 133.0 Build 5932.85
OperaOpera 133.0 Build 5932.85 PhotoshopAdobe Photoshop CC 2026 27.8
PhotoshopAdobe Photoshop CC 2026 27.8 OKXOKX - Buy Bitcoin or Ethereum
OKXOKX - Buy Bitcoin or Ethereum WPS OfficeWPS Office
WPS OfficeWPS Office Adobe AcrobatAdobe Acrobat Pro 2026.001.21691
Adobe AcrobatAdobe Acrobat Pro 2026.001.21691 CleamioCleamio 3.4.0
CleamioCleamio 3.4.0 MalwarebytesMalwarebytes 5.24.0
MalwarebytesMalwarebytes 5.24.0 TradingViewTradingView - Track All Markets
TradingViewTradingView - Track All Markets CleanMyMacCleanMyMac X 5.2.10
CleanMyMacCleanMyMac X 5.2.10 AdGuard VPNAdGuard VPN for Mac 2.9.0
AdGuard VPNAdGuard VPN for Mac 2.9.0
Comments and User Reviews