-
Latest Version
-
Operating System
macOS 10.12 Sierra or later
-
User Rating
Click to vote -
Author / Product
-
Filename
mysql-8.0.20-macos10.15-x86_64.dmg
Sometimes latest versions of the software can cause issues when installed on older devices or devices running an older version of the operating system.
Software makers usually fix these issues but it can take them some time. What you can do in the meantime is to download and install an older version of MySQL 8.0.20.
For those interested in downloading the most recent release of MySQL for Mac or reading our review, simply click here.
All old versions distributed on our website are completely virus-free and available for download at no cost.
We would love to hear from you
If you have any questions or ideas that you want to share with us - head over to our Contact page and let us know. We value your feedback!
-
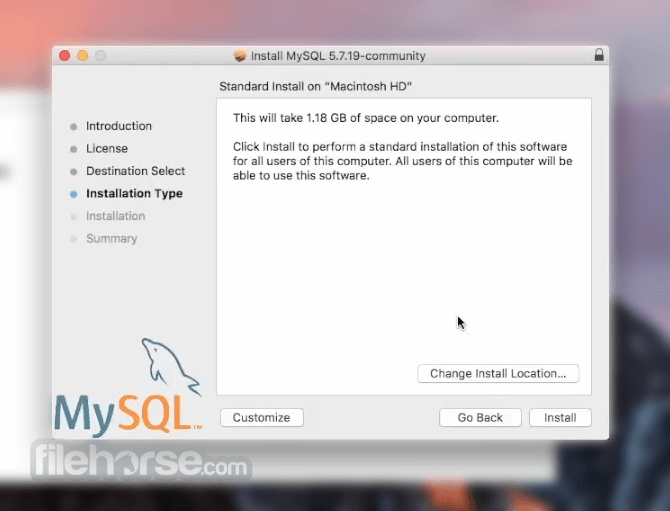
MySQL 8.0.20 Screenshots
The images below have been resized. Click on them to view the screenshots in full size.

-

-
-

-

What's new in this version:
Functionality Added or Changed:
- Important Change: Previously, including any column of a blob type larger than TINYBLOB or BLOB as the payload in an ordering operation caused the server to revert to sorting row IDs only, rather than complete rows; this resulted in a second pass to fetch the rows themselves from disk after the sort was completed. Since JSON and GEOMETRY columns are implemented internally as LONGBLOB, this caused the same behavior with these types of columns even though they are almost always much shorter than the 4GB maximum for LONGBLOB (or even the 16 MB maximum for MEDIUMBLOB). The server now converts columns of these types into packed addons in such cases, just as it does TINYBLOB and BLOB columns, which in testing showed a significant performance increase. The handling of MEDIUMBLOB and LONGBLOB columns in this regard remains unchanged.
- One effect of this enhancement is that it is now possible for Out of memory errors to occur when trying to sort rows containing very large (multi-megabtye) JSON or GEOMETRY column values if the sort buffers are of insufficient size; this can be compensated for in the usual fashion by increasing the value of the sort_buffer_size system variable. (Bug #30400985, Bug #30804356)
- InnoDB: The Contention-Aware Transaction Scheduling (CATS) algorithm, which prioritizes transactions that are waiting for locks, was improved. Transaction scheduling weight computation is now performed a separate thread entirely, which improves computation performance and accuracy.
- The First In First Out (FIFO) algorithm, which had also been used for transaction scheduling, was removed. The FIFO algorithm was rendered redundant by CATS algorithm enhancements. Transaction scheduling previously performed by the FIFO algorithm is now performed by the CATS algorithm.
- A TRX_SCHEDULE_WEIGHT column was added to the INFORMATION_SCHEMA.INNODB_TRX table, which permits querying transaction scheduling weights assigned by the CATS algorithm.
Bugs Fixed:
- Performance: Certain queries against tables with spatial indexes were not performed as efficiently following an upgrade from MySQL 5.7 to MySQL 8.0
- References: See also: Bug #89551, Bug #27499984
- NDB Cluster: NDB defines one SPJ worker per node owning a primary partition of the root table. If this table used read from any replica, DBTC put all SPJ workers in the same DBSPJ instance, which effectively removed the use of some SPJ workers.
- NDB Cluster: Executing the SHOW command using an ndb_mgm client binary from NDB 8.0.16 or earlier to access a management node running NDB 8.0.17 or later produced the error message Unknown field: is_single_user.
- InnoDB: A CREATE UNDO TABLESPACE operation that specified an undo data file name without specifying a path removed an existing undo data file of the same name from the directory specified by innodb_undo_directory variable. The file name conflict check was performed on the data directory instead of the directory specified by the innodb_undo_directory variable.
- InnoDB: In debug builds, a regression introduced in MySQL 8.0.19 slowed down mutex and rw-lock deadlock debug checks.
- References: This issue is a regression of: Bug #30628872.
- InnoDB: Valgrind testing raised an error indicating that a conditional jump or move depends on an uninitialized value. The error was a false-positive due to invalid validation logic.
- InnoDB: Missing barriers in rw_lock_debug_mutex_enter() (in source file sync0debug.cc) could cause a thread to wait without ever being woken up.
- InnoDB: To improve server initialization speed, fallocate() is now used to allocate space for redo log files.
- InnoDB: A data dictionary table open function was implemented with incorrect lock ordering
- InnoDB: Changes to parallel read threads functionality introduced in MySQL 8.0.17 caused a degradation in SELECT COUNT(*) performance. Pages were read from disk unnecessarily
- InnoDB: DDL logging was not performed for SQL operations executed by the bootstrap thread using the init_file startup variable, causing files to be left behind that should have been removed during a post-DDL stage.
- InnoDB: Adding an index on a column cast as a JSON array on a table with a specific number of records failed with an “Incorrect key file for table” error.
- InnoDB: A Valgrind error reported that an uninitialized lock->writer_thread value was used in a conditional jump.
- InnoDB: An internal buffer pool statistics counter (n_page_gets) was partitioned by page number to avoid contention when accessed by multiple threads.
- InnoDB: A tablespace import operation failed with a schema mismatch error due to the .cfg file and the data dictionary both containing default values for a column that was added using ALGORITHM=INSTANT. An error should only occur if default values differ.
- InnoDB: A slow shutdown failed to flush some GTIDs, requiring recovery of unflushed GTIDs from the undo log.
- InnoDB: A broken alignment requirement in the code that allocates a prefix in memory for Performance Schema memory allocations caused a failure on MySQL builds optimized for macOS and FreeBSD.
- InnoDB: Adding a virtual column raised an assertion failure due to data that was missing from the new data dictionary object created for the table.
- InnoDB: A required latch was not taken when checking the mode of an undo tablespace. A required latch was also not taken when checking whether an undo tablespace is empty
- InnoDB: Allocating an update undo log segment to an XA transaction for persisting a GTID value before the transaction performed any data modifications caused a failure.
- InnoDB: A query executed on a partitioned table with a discarded tablespace raised an assertion failure.
- InnoDB: The row_upd_clust_rec_by_insert function, which marks a clustered index record as deleted and inserts an updated version of the record into the clustered index, passed an incorrect n_ext value (the total number of external fields) to lower level functions, causing an assertion failure.
- InnoDB: During a cloning operation, writes to the data dictionary buffer table at shutdown were too late, causing a failure. Newly generated dirty pages were not being flushed.
- InnoDB: An operation performed with the innodb_buffer_pool_evict debug variable set to uncompressed caused an assertion failure.
- InnoDB: Read-write lock code (rw_lock_t) that controls ordering of access to the boolean recursive flag and the writer thread ID using GCC builtins or os_mutex when the builtins are not available, was revised to use C++ std::atomic in some instances.
- Thanks to Yibo Cai from ARM for the contribution.
- InnoDB: A failure occurred while upgrading from MySQL 5.7 to MySQL 8.0. A server data dictionary object was missing information about the FTS_DOC_ID column and FTS_DOC_ID_INDEX that remain after dropping a FULLTEXT index.
- InnoDB: Unnecessary messages about parallel scans were printed to the error log.
- InnoDB: During upgrade from MySQL 5.7 to MySQL 8.0, clustered indexes named GEN_CLUST_INDEX are renamed to PRIMARY, which resulted in duplicate entries for the clustered indexes being added to the mysql.innodb_index_stats table.
- InnoDB: Various internal functions computed write event slots in an inconsistent manner.
- InnoDB: Under specific circumstances, it was possible that tablespace encryption key information would not be applied during the redo log apply phase of crash recovery.
- InnoDB: A file operation failure caused the page tracking archiver to fail, which in turn caused the main thread to hang, resulting in an assertion failure. Also, incorrectly, the page tracking archiver remained enabled in innodb_read_only mode.
- InnoDB: An index corruption error was reported when attempting to import a tablespace containing a table column that was added using ALGORITHM=INSTANT. The error was due to missing metadata associated with the instantly added column.
- InnoDB: A transaction attempting to fetch an LOB record encountered a null LOB reference, causing an assertion failure. However, the null LOB reference was valid in this particular scenario because the LOB value was not yet fully written.
- InnoDB: During a parallel read operation, the rollback of a table load operation while autocommit was disabled resulted in a server to exit due to assertion code that did not account for the possibility of tree structure changes during a parallel read.
- InnoDB: The current size value maintained in a rollback segment memory object was found to be invalid, causing an assertion failure in function trx_purge_free_segment(). A validation routine (trx_rseg_t::validateCurrSize()) was added to verify the current size value.
- InnoDB: A prepared statement executed with invalid parameter values raised an assertion failure.
- InnoDB: An add column operation caused an assertion failure. The failure was due to a dangling pointer.
- References: This issue is a regression of: Bug #28491099.
- InnoDB: Updating certain InnoDB system variables that take string values raised invalid rad errors during Valgrind testing.
- InnoDB: Redo log records for modifications to undo tablespaces increased in size in MySQL 8.0 due to a change in undo tablespace ID values, which required additional bytes. The change in redo log record size caused a performance regression in workloads with heavy write I/O. To address this issue, the redo log format was modified to reduce redo log record size for modifications to undo tablespaces.
- InnoDB: Additional information about InnoDB file writes, including progress data, is now printed to the error log.
- InnoDB: An insert statement on a table with a spatial index raised a record type mismatch assertion due to a tuple corruption.
- InnoDB: A function that calculates undo log record size could calculate an incorrect length value in the case of a corrupted undo log record, resulting in a malloc failure. Assertion code was added to detect incorrect calculations.
- Replication: The thread used by Group Replication's message service was not correctly registered by the Performance Schema instrumentation, so the thread actions were not visible in Performance Schema tables.
- Replication: Group Replication initiates and manages cloning operations for distributed recovery, but group members that have been set up to support cloning may also participate in cloning operations that a user initiates manually. In releases before MySQL 8.0.20, you could not initiate a cloning operation manually if the operation involved a group member on which Group Replication was running. From MySQL 8.0.20, you can do this, provided that the cloning operation does not remove and replace the data on the recipient. The statement to initiate the cloning operation must therefore include the DATA DIRECTORY clause if Group Replication is running.
- Replication: For Group Replication channels, issuing the CHANGE MASTER TO statement with the PRIVILEGE_CHECKS_USER option while Group Replication was running caused the channel's relay log files to be deleted. Transactions that had been received and queued in the relay log, but not yet applied, could be lost in this situation. The CHANGE MASTER TO statement can now only be issued when Group Replication is not running.
- Replication: Group Replication's failure detection mechanism raises a suspicion if a server stops sending messages, and the member is eventually expelled provided that a majority of the group members are still communicating. However, the failure detection mechanism did not take into account the situation where one or more of the group members in the majority had actually already been marked for expulsion, but had not yet been removed from the group. Where the network was unstable and members frequently lost and regained connection to each other in different combinations, it was possible for a group to end up marking all its members for expulsion, after which the group would cease to exist and have to be set up again.
- Group Replication's Group Communication System (GCS) now tracks the group members that have been marked for expulsion, and treats them as if they were in the group of suspect members when deciding if there is a majority. This ensures at least one member remains in the group and the group can continue to exist. When an expelled member has actually been removed from the group, GCS removes its record of having marked the member for expulsion, so that the member can rejoin the group if it is able to. (Bug #30640544)
- Replication: While an SQL statement was in the process of being rewritten for the binary log so that sensitive information did not appear in plain text, if a SHOW PROCESSLIST statement was used to inspect the query, the query could become corrupted when it was written to the binary log, causing replication to stop. The process of rewriting the query is now kept private, and the query thread is updated only when rewriting is complete.
- Replication: When a GRANT or REVOKE statement is only partially executed, an incident event is logged in the binary log, which makes the replication slave's applier thread stop so that the slave can be reconciled manually with the master. Previously, if a failed GRANT or REVOKE statement was the first statement executed in the session, no GTID was applied to the incident event (because the cache manager did not yet exist for the session), causing an error on the replication slave. Also, no incident event was logged in the situation where a GRANT statement created a user but then failed because the privileges had been specified incorrectly, again causing an error on the replication slave. Both these issues have now been fixed.
- Replication: Compression is now triggered for the mysql.gtid_executed table when the thread/sql/compress_gtid_table thread is launched after the server start, and the effects are visible when the compression process is complete.
- Replication: Performance Schema tables could not be accessed on a MySQL server with Group Replication that was running under high load conditions.
- Replication: Internal queries from Group Replication to the Performance Schema for statistics on local group members failed if they occurred simultaneously with changes to the group's membership. Locking for the internal queries has been improved to fix the issue.
- Replication: In the event of an unplanned disconnection of a replication slave from the master, the reference to the master's dump thread might not be removed from the list of registered slaves, in which case statements that accessed the list of slaves would fail. The issue has now been fixed. (Bug #29915479)
- Replication: When a partitioned table was involved, the server did not correctly handle the situation where a row event could not be written to the binary log due to a lack of cache space. An appropriate error is now returned in this situation.
- Replication: During Group Replication's distributed recovery process, if a joining member is unable to complete a remote cloning operation with any donor from the group, it uses state transfer from a donor's binary log to retrieve all of the required data. However, if the last attempted remote cloning operation was interrupted and left the joining member with incomplete or no data, an attempt at state transfer immediately afterwards could also fail. Before attempting state transfer following a failed remote cloning operation, Group Replication now checks that the remote cloning operation did not reach the stage of removing local data from the joining member. If data was removed, the joining member leaves the group and takes the action specified by the group_replication_exit_state_action system variable.
- Replication: With the settings binlog_format=MIXED, tx_isolation=READ-COMMITTED, and binlog_row_image=FULL, an INSERT ... SELECT query involving a transactional storage engine omitted any columns with a null value from the row image written to the binary log. This happened because when processing INSERT ... SELECT statements, the columns were marked for inserts before the binary logging format was selected. The issue has now been fixed.
- Replication: Before taking certain actions, Group Replication checks what transactions are running on the server. Previously, the service used for this check did not count transactions that were in the commit phase, which could result in the action timing out. Now, transactions that are in the commit phase are included in the set of currently ongoing transactions.
- JSON: When JSON_TABLE() was used as part of an INSERT statement in strict mode, conversion errors handled by any ON ERROR clause could cause the INSERT to be rejected. Since errors are handled by an ON ERROR clause, the statement should not be rejected unless ERROR ON ERROR is actually specified.
- This issue is fixed by ignoring warnings when converting values to the target type if NULL ON ERROR or DEFAULT ... ON ERROR has been specified or is implied.
 OperaOpera 133.0 Build 5932.34
OperaOpera 133.0 Build 5932.34 PhotoshopAdobe Photoshop CC 2026 27.8
PhotoshopAdobe Photoshop CC 2026 27.8 OKXOKX - Buy Bitcoin or Ethereum
OKXOKX - Buy Bitcoin or Ethereum WPS OfficeWPS Office
WPS OfficeWPS Office Adobe AcrobatAdobe Acrobat Pro 2026.001.21691
Adobe AcrobatAdobe Acrobat Pro 2026.001.21691 CleamioCleamio 3.4.0
CleamioCleamio 3.4.0 MalwarebytesMalwarebytes 5.24.0
MalwarebytesMalwarebytes 5.24.0 TradingViewTradingView - Track All Markets
TradingViewTradingView - Track All Markets CleanMyMacCleanMyMac X 5.2.10
CleanMyMacCleanMyMac X 5.2.10 AdGuard VPNAdGuard VPN for Mac 2.9.0
AdGuard VPNAdGuard VPN for Mac 2.9.0
Comments and User Reviews